 Marina Lubimova
Marina Lubimova

The most important line inside Marvell Technology’s latest earnings report was not quarterly revenue growth. It was the repeated emphasis on custom XPUs and AI interconnect systems.
That shift points to something larger than another strong semiconductor quarter. The economics of hyperscale AI are starting to push cloud giants toward proprietary infrastructure rather than complete dependence on standardized GPU ecosystems.
Marvell reported fiscal Q1 2027 revenue of $2.418 billion, up 28% year over year and above prior guidance. The company also guided next-quarter revenue to roughly $2.7 billion, reflecting continued acceleration tied directly to AI datacenter demand.
The first phase of the AI boom rewarded whoever controlled compute. The next phase may reward whoever helps hyperscalers reduce dependence on that concentration.
Marvell highlighted accelerating demand tied to custom XPUs, optical interconnects, scale-out networking, and hyperscale AI systems.
The AI trade revolved around a relatively simple assumption: more GPUs meant more AI growth. That framework is starting to evolve. Training and operating frontier AI models increasingly requires hyperscalers to optimize:
- networking efficiency,
- power consumption,
- memory bandwidth,
- latency,
- and workload-specific silicon architectures.
At massive scale, standardized compute alone becomes economically inefficient. That is why custom silicon is suddenly becoming one of the most important themes inside AI infrastructure.
Hyperscalers Are Quietly Building More Proprietary AI Stacks
The AI market is starting to fragment into specialized infrastructure layers. Cloud giants no longer want to rely entirely on off-the-shelf acceleration if custom architectures can:
- lower costs,
- improve energy efficiency,
- reduce bottlenecks,
- or optimize specific AI workloads.
That transition is creating new demand for companies operating deeper inside the infrastructure stack:
- networking systems,
- optical connectivity,
- advanced packaging,
- memory integration,
- and custom accelerator ecosystems.
Institutional capital is increasingly spreading beyond GPU manufacturers into networking, memory, and custom AI infrastructure companies.
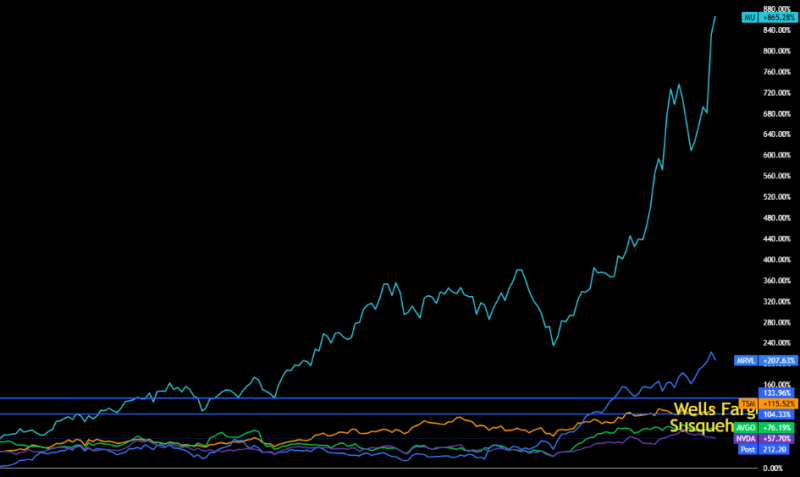
Key performance:
- MU +865%
- MRVL +207%
- TSM +115%
- AVGO +76%
- NVDA +57%
The divergence is becoming harder to ignore. Markets treated Nvidia as the dominant scarcity layer. Supporting infrastructure suppliers remained secondary beneficiaries inside the trade. Now some of those infrastructure names are rerating faster than portions of the original AI leadership itself.
Markets are beginning to price AI not as a single-company compute story, but as a broader architectural transformation across datacenters.
The Bottleneck Is Moving Away From Raw Compute
Marvell’s earnings repeatedly referenced:
- scale-out networking,
- optical interconnect modules,
- custom AI silicon,
- and XPU attachment systems.
Those categories matter because AI scaling is increasingly constrained by data movement rather than raw processing power alone. The challenge is no longer simply generating more compute.
It is synchronizing massive AI clusters efficiently without overwhelming:
- power systems,
- cooling capacity,
- networking bandwidth,
- or latency thresholds.
As models become larger and more distributed, the supporting infrastructure becomes economically critical. That changes the nature of the AI trade itself.
AI Is Starting to Look Like an Industrial Capex Cycle
Infrastructure cycles rarely behave like software cycles. Once hyperscalers commit tens of billions of dollars toward:
- custom silicon,
- networking fabrics,
- optical systems,
- and datacenter redesigns,
- the spending inertia becomes difficult to reverse quickly.
That is one reason the current AI boom increasingly resembles an industrial buildout rather than a traditional software expansion. The market is slowly moving deeper into the plumbing layer of the AI economy. The first phase rewarded ownership of GPUs.
The next phase may reward whichever companies help hyperscalers build AI systems that are cheaper to operate, less power-intensive, and less dependent on a single compute supplier.
 Marina Lubimova
Marina Lubimova


